Uptime is measurable availability
It shows the share of time a service is reachable and usable, not just whether the infrastructure exists.
Uptime monitoring with UptimeTick gives SaaS teams, developers, and operations groups continuous availability tracking across websites, servers, APIs, certificates, and scheduled jobs. Detect downtime early, verify real incidents, and send uptime alerts fast enough to protect reliability and service continuity.
Continuous availability tracking
Watch production services around the clock and see when availability actually changes.
Incident detection built for action
Confirm failures quickly, open incidents faster, and route uptime alerts to the right people.
Reliable history you can report on
Review uptime percentage, downtime events, and service continuity over time.

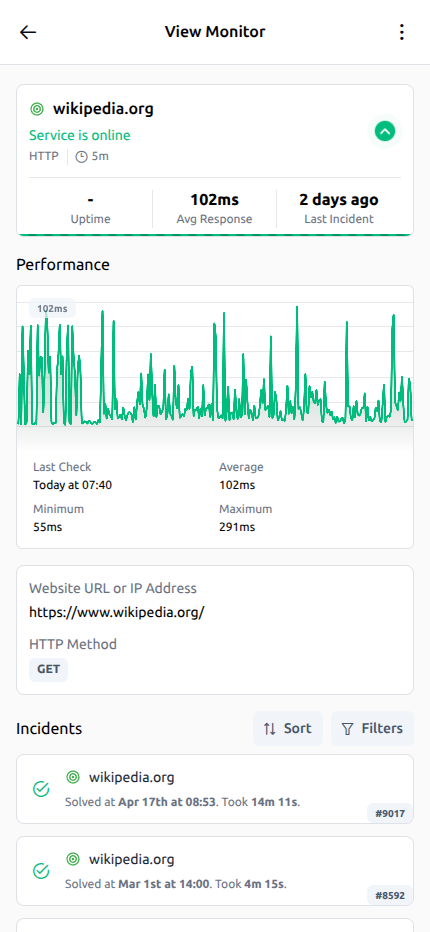
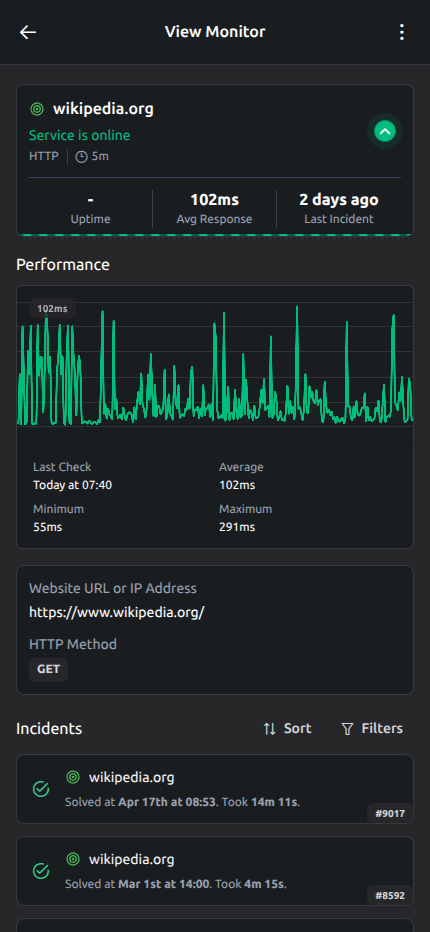
Checks, incidents, alert context, and recovery history stay in one place so your team can investigate faster.
Outage timeline
See when an incident started, how it progressed, and when service fully recovered.
Response time trends
Track performance shifts and spot slowdowns before they affect the user experience.
Alert context in one view
Checks, incident history, and critical signals stay together to speed up investigation.
Uptime is the percentage of time a service stays available and usable. An uptime monitoring service measures that availability with repeated checks, tracks when downtime starts and ends, and turns those events into records your team can act on. Instead of relying on customer complaints, you get direct evidence of when a system was reachable, how often it failed, and whether reliability is improving over time.
Availability percentage matters because it converts technical performance into a business signal. If a core service drops, the interruption affects service continuity immediately: sign-ins stop, queues back up, checkouts fail, integrations stall, and internal teams lose visibility. That is why monitor uptime data needs to be clear, time-based, and tied to real incidents rather than vague status snapshots.
For page-level checks on customer-facing sites and rendered content, start with website monitoring.
It shows the share of time a service is reachable and usable, not just whether the infrastructure exists.
Even short outages interrupt logins, purchases, workflows, scheduled jobs, and customer trust.
Uptime percentage gives teams a consistent way to track reliability and compare performance against SLAs.
In production, a useful uptime monitor does more than send a single request and say up or down. It runs regular checks, confirms repeated failures, opens an incident when an outage is real, and generates alerts that help the right team respond quickly. That workflow reduces false positives while still keeping detection fast.
UptimeTick runs checks on the cadence you choose, so you can monitor uptime continuously across critical services.
When a check fails, repeated verification helps separate a real outage from a transient network issue.
Confirmed failures become actionable incidents with timestamps, affected monitors, and recovery tracking.
Teams receive uptime alerts by email and mobile push so they can start remediation before downtime spreads.
Uptime percentages make reliability easier to understand because they turn availability into a shared standard. They are also closely tied to SLAs, post-incident reviews, and customer expectations. When a team says a service should stay at 99.9% uptime, that target sets a practical limit for how much downtime is acceptable in a month.
Why does 99.9% matter so much? It is demanding enough to expose recurring issues, but realistic enough for many growing SaaS products and business systems. If you cannot measure uptime percentage consistently, it is difficult to know whether reliability is improving, whether response is fast enough, or whether service continuity targets are actually being met.
Roughly 7 hours of monthly downtime. That level can be painful for customer-facing SaaS or online stores.
Around 43 minutes of monthly downtime. It is a common reliability target because it keeps outages visible and manageable.
Only a few minutes of downtime per month. Reaching it usually requires tighter monitoring, faster response, and stronger operational discipline.
Match your plan to the number of services, checks, and alerting needs your team depends on.
Uptime monitoring covers more than one public webpage. Reliable services depend on endpoints, infrastructure, certificates, and background processes all staying available together.
When you need host reachability at the network layer, add ICMP ping monitoring.
For endpoints that must return the right status codes and payloads, layer in API monitoring.
Website uptime monitoring is the front line for digital services. It tells you whether a customer-facing experience is reachable, returns the expected response, and stays available during traffic spikes, deploys, or third-party failures.
UptimeTick checks public websites and web apps over HTTP(s), helping teams detect outages, follow latency, and confirm that a real page is being served instead of an error template or broken response.
Server uptime monitoring focuses on whether the infrastructure behind your service is reachable. That matters for application servers, internal nodes, edge systems, and any environment where network reachability is the earliest sign of trouble.
With ping monitoring and port monitoring, UptimeTick helps operations teams detect downtime on the systems that support customer traffic, admin tools, and internal workloads before a small incident becomes a larger service disruption.
An API can return a 200 response and still fail the business workflow, so API uptime monitoring needs more than a simple handshake. Reliable API checks confirm that endpoints respond on time and return the content or status your application depends on.
UptimeTick helps developers and SaaS teams monitor uptime for authentication services, core product APIs, webhooks, and partner integrations where availability directly affects user experience and downstream automation.
Some availability incidents are caused by trust failures rather than raw downtime. An expired or misconfigured certificate can make a service effectively unavailable even when the host is still responding.
UptimeTick pairs SSL monitoring with uptime checks so teams can catch certificate risk early, avoid preventable outages, and maintain continuity for browsers, APIs, and automated clients that require valid TLS.
Not every important workload exposes an endpoint. Scheduled jobs, import pipelines, background workers, and backup tasks often fail silently unless you verify that they reported in on time.
Heartbeat monitoring lets UptimeTick confirm those expected signals arrive as planned. When a job misses its window, your team gets an uptime alert tied to a specific process instead of discovering the issue after customers notice missing data or delayed processing.
Launch a monitor in minutes and keep websites, servers, APIs, SSL, and heartbeat checks visible from one dashboard.
Renewal-related outages sit outside normal app checks, so broader resilience also benefits from domain expiry monitoring.
Early detection is what turns uptime monitoring from reporting into operations. The sooner you identify an outage or reliability drop, the sooner you can preserve customer experience, reduce revenue loss, and keep teams aligned on a real incident timeline.
To catch certificate problems before they turn into availability incidents, pair uptime tracking with SSL monitoring.
Users may forgive an incident, but repeated availability issues make your service feel unreliable and risky.
Downtime can block trials, transactions, sign-ins, and renewal workflows while support and engineering costs rise.
Persistent outages and unstable availability can hurt crawl reliability and create a weaker experience for search-driven traffic.
Without early detection, teams lose the timeline they need to isolate causes, coordinate response, and protect service continuity.
UptimeTick is designed for teams that want practical uptime monitoring without a heavy setup process. You get the monitor types needed for real production systems, fast uptime alerts, mobile visibility, and historical records that make reliability easier to explain.
Create an uptime monitor in minutes with HTTP(s), ping, port, SSL, heartbeat, domain, and keyword checks in one product.
Email and mobile push notifications help the right responders see incidents fast instead of waiting for customer reports.
Use UptimeTick mobile apps to review monitor status, active incidents, and recovery progress when you are away from your desk.
Review uptime percentage, incident duration, and reliability trends over time for retrospectives, reporting, and SLA conversations.
Different teams use uptime monitoring for different reasons, but the common goal is the same: maintain availability and reduce the impact of downtime before it disrupts users or operations.
Track customer-facing apps, auth endpoints, background jobs, and billing flows where uptime directly affects retention and expansion.
Monitor storefronts, checkouts, payment callbacks, and SSL health so downtime does not quietly interrupt revenue.
Watch admin tools, intranet apps, VPN endpoints, and scheduled workflows that teams rely on for day-to-day operations.
Monitor public and private endpoints that power mobile apps, integrations, automation, and partner-facing services.
Clear answers for teams comparing uptime monitors and evaluating operational fit.
Uptime monitoring is the process of checking whether a service stays available over time, detecting downtime, and alerting teams when an outage or incident affects reliability.