Endpoint checks verify more than reachability
A useful check confirms that an API route responds correctly, not just that a host accepted a connection.
API monitoring with UptimeTick helps developers, backend teams, SaaS founders, and DevOps groups monitor API endpoints for availability, latency, timeout behavior, and invalid responses so incidents are detected before product flows, integrations, or customers are affected.
Endpoint reliability monitoring
Track whether critical API routes stay reachable, responsive, and valid over time.
Response validation that goes beyond uptime
Confirm status codes, expected content, and payload integrity instead of trusting a simple connection check.
Fast API downtime alerts
Notify the right team quickly when an endpoint slows down, times out, or starts returning bad responses.
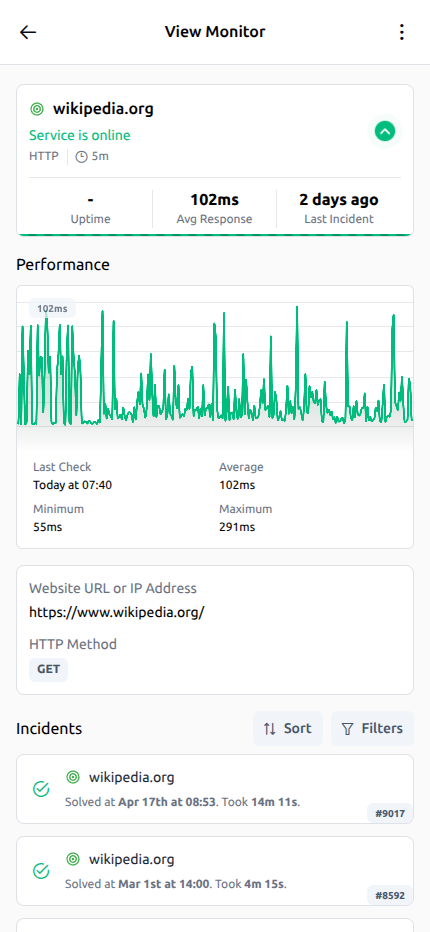
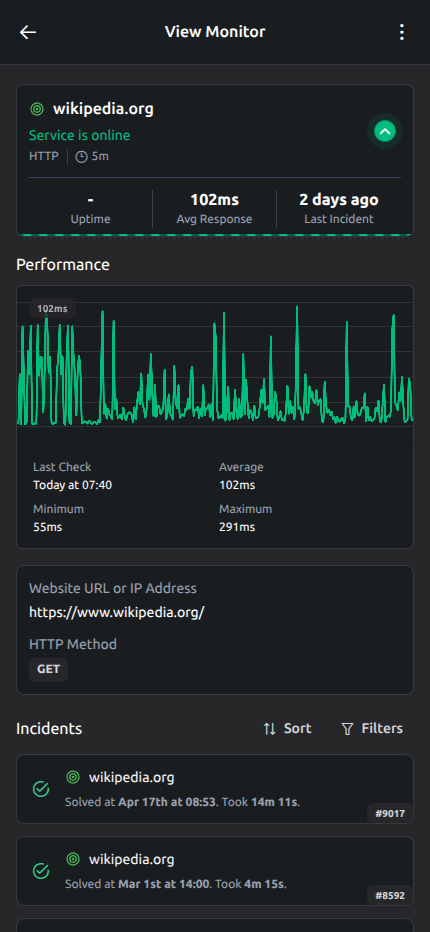
Checks, incidents, alert context, and recovery history stay in one place so your team can investigate faster.
Outage timeline
See when an incident started, how it progressed, and when service fully recovered.
Response time trends
Track performance shifts and spot slowdowns before they affect the user experience.
Alert context in one view
Checks, incident history, and critical signals stay together to speed up investigation.
API monitoring is the practice of sending repeated requests to an endpoint and checking whether the response matches what your application expects. An API monitoring tool does not just ask whether a route is online. It tracks endpoint availability, response codes, latency, timeout behavior, and response content so teams can tell whether an API is actually usable in production.
That matters because APIs often fail silently. A response can still return from the server while the business workflow is broken underneath: authentication may degrade, a webhook may stop delivering the right payload, a payment endpoint may slow down, or a partner integration may begin returning invalid data. Without active endpoint monitoring, these failures can sit unnoticed until users, customers, or dependent systems start reporting a problem.
For a broader reliability view across endpoints, sites, certificates, and jobs, connect this page with uptime monitoring.
A useful check confirms that an API route responds correctly, not just that a host accepted a connection.
An API can stay technically available while still returning the wrong status code, timing out, or producing a bad payload.
Backend issues often appear first in broken integrations and delayed workflows, long before a customer files a support ticket.
In production, API uptime monitoring should reflect how real systems depend on an endpoint. That means sending regular requests, checking the response code, measuring latency, watching for timeouts, and validating the returned content. The goal is not just to know that something answered, but to know whether the API answered correctly and fast enough to support the workflow behind it.
UptimeTick sends requests to the API routes you define so endpoint health is checked continuously instead of manually.
Expected HTTP status codes help confirm that the endpoint returned a successful result rather than a redirect, client error, or server error.
If an endpoint hangs too long or fails to return within the expected window, the monitor can flag a timeout incident before users experience stalled workflows.
Keyword and response checks help confirm that the payload still contains the fields, values, or markers your integration depends on.
Reliable API response monitoring should reveal more than full downtime. Many API incidents start as partial failures, degraded response behavior, or invalid data coming back from an otherwise reachable service.
Certificate and TLS problems can break healthy endpoints too, so pair API checks with SSL monitoring.
One of the earliest signals in API status monitoring is an unexpected response code. A route that should return 200 may start returning 401, 403, 404, 429, or 500 depending on the failure mode. Those shifts often point to deployment mistakes, authorization problems, dependency issues, or upstream overload.
Tracking response code changes matters because application failures do not always look like downtime from the outside. An API may still answer requests while breaking every dependent workflow that expects a specific success response.
An endpoint can remain available while getting slower and slower under load, during database contention, or while waiting on third-party services. That is why an API monitoring tool should measure latency continuously, not only confirm that a response eventually arrived.
Latency trends help teams understand whether performance is degrading toward an incident. If a route normally returns in a few hundred milliseconds and suddenly stretches toward seconds, users may feel the impact before a hard outage appears.
Timeouts are often the most disruptive API failures because they hold application workflows open while nothing useful comes back. This can affect checkouts, sign-ins, callbacks, mobile sync, queue workers, and any automation that expects a fast response from a backend endpoint.
When timeout detection is built into monitoring, teams can identify these stalls as a distinct incident type instead of treating them as vague slowness. That makes troubleshooting much faster.
A 200 response does not guarantee that an API did the right thing. A route can return a success code while the payload is missing a required field, contains the wrong value, or sends an error message in a response body that still looks technically successful.
That is why response validation matters in API uptime monitoring. Checking for expected JSON markers, message fragments, or keywords helps detect functional failures that pure status checks will miss.
Some API incidents begin at the transport and trust layer instead of inside the application logic. A certificate problem can make an otherwise healthy endpoint unavailable to clients, automated jobs, and integrations that require valid TLS.
Pairing SSL monitoring with API checks helps teams catch certificate-related incidents before they turn into authentication failures, failed webhooks, or broken partner traffic.
Cover critical APIs first, then grow into broader endpoint, latency, and response validation coverage.
Strong endpoint monitoring combines uptime signals, response validation, and alerting so teams can act on both obvious and subtle API failures.
If failures may start at the host or routing layer, use network reachability monitoring alongside endpoint checks.
Endpoint uptime checks confirm that a route can be reached consistently and returns a response instead of failing outright. This is the baseline for API availability tracking and the first signal most teams need during an incident.
Used well, these checks help backend and DevOps teams see whether a failure is isolated to one route, spreading across a service, or tied to a broader infrastructure problem.
API response monitoring should make latency visible, not just uptime. A route that stays online but gets slower still creates a production problem for dashboards, mobile apps, queues, and synchronous product flows.
Historical timing data helps teams compare normal behavior against deploys, traffic spikes, dependency failures, and known incidents. That context is essential for understanding whether performance is stable or drifting in the wrong direction.
Many backend teams need more than status code validation. They need confidence that the API still returns the structure or values their applications rely on. For JSON-based endpoints, that means checking for expected fields, markers, or content inside the response body.
UptimeTick helps teams validate expected response content so a technically successful request does not hide a broken payload or incomplete result.
Keyword checks are useful when an endpoint should return a known phrase, identifier, field name, or business-state marker. This is practical for APIs that expose predictable values in responses and for cases where a full parser is unnecessary.
Used carefully, response keyword checks help teams detect silent regressions in auth flows, webhook acknowledgements, partner integrations, and operational APIs.
Monitoring only matters when it leads to action. Once an endpoint fails checks, slows beyond acceptable latency, times out, or starts returning invalid content, the right team needs a clear alert with enough context to respond immediately.
UptimeTick turns confirmed API failures into actionable incidents with alerts and historical records, making it easier to shorten the gap between detection and response.
APIs sit behind product features, automations, partner integrations, billing flows, and internal tooling. When they fail quietly, the damage spreads faster than teams expect because the breakage often shows up downstream first.
Third-party and internal integrations depend on predictable endpoint behavior, not just a reachable URL.
Response validation and timeout tracking expose incidents that users may not notice until business workflows are already broken.
Stable APIs support product reliability, partner confidence, and fewer support escalations when traffic is under pressure.
Fast monitoring and alerts help teams respond before customers, partners, or internal users are the first to report the issue.
UptimeTick gives teams a practical API monitoring tool with the checks needed for real production endpoints. You can start quickly, validate responses, receive fast alerts, and keep incident history accessible without building a fragmented monitoring workflow.
Create endpoint checks in minutes with HTTP(s) monitoring, keyword validation, SSL tracking, and supporting monitor types in one platform.
Email and mobile notifications help responders act quickly when an endpoint fails, slows down, or starts returning invalid responses.
Review incident timelines, response behavior, and past failures so debugging and post-incident reviews are grounded in real data.
Use UptimeTick mobile apps to review monitor status and active incidents when you are away from your workstation.
Different teams rely on API monitoring for different reasons, but the common goal is the same: keep endpoints dependable enough that product and integration workflows do not fail in silence.
Monitor authentication, account, billing, search, and product-data endpoints that power customer-facing features and internal operations.
Track transaction, authorization, and callback routes where timeout incidents or invalid responses can affect revenue immediately.
Watch inbound and outbound webhook flows so delivery failures, bad payloads, and latency regressions do not quietly break automation.
Monitor private APIs between services, admin systems, and automation layers where hidden backend failures can ripple through operations.
Clear answers for teams evaluating endpoint monitoring and API uptime monitoring tools.
For rendered pages and user-facing content, website monitoring for user-facing pages is usually the better fit.
API monitoring is the process of checking endpoints on a recurring basis to confirm availability, validate response codes and content, measure latency, and detect incidents such as timeouts or invalid payloads.