El uptime es disponibilidad medible
Muestra qué parte del tiempo un servicio estuvo realmente accesible y utilizable, no solo si la infraestructura existía.
Uptime monitoring con UptimeTick da a equipos SaaS, developers y operaciones seguimiento continuo de disponibilidad en sitios web, servidores, APIs, certificados y tareas programadas. Detecta el downtime pronto, confirma incidentes reales y envía uptime alerts lo bastante rápido como para proteger la fiabilidad y la continuidad del servicio.
Seguimiento continuo de disponibilidad
Observa servicios en producción todo el tiempo y detecta cuándo cambia la disponibilidad real.
Detección de incidentes orientada a la acción
Confirma fallos rápido, abre incidentes antes y dirige las uptime alerts a las personas adecuadas.
Historial fiable para reportar
Revisa uptime percentage, eventos de downtime y continuidad del servicio a lo largo del tiempo.

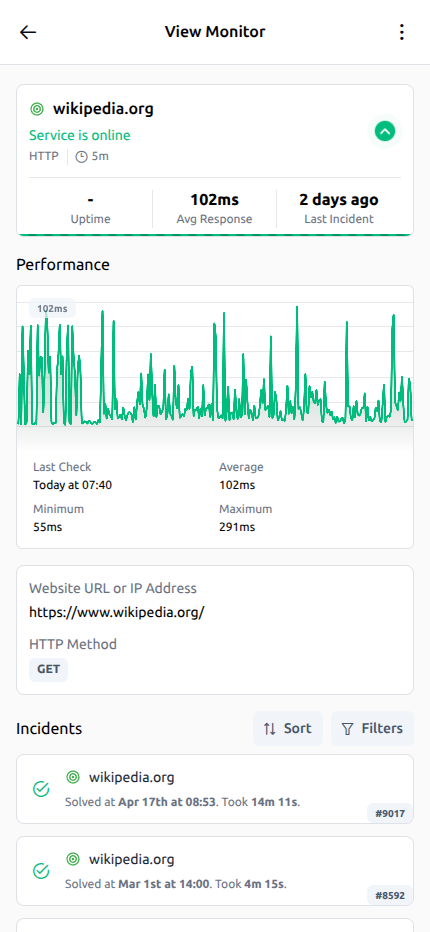
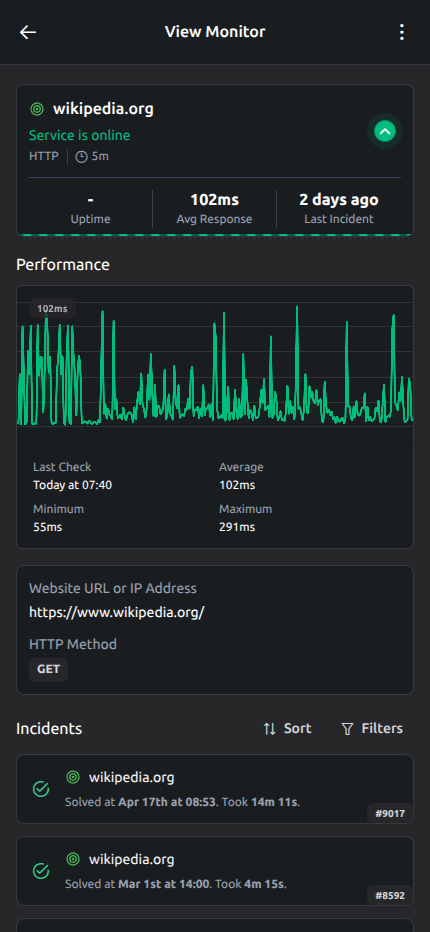
Checks, incidentes, contexto de alerts e historial de recovery quedan en una sola vista para investigar más rápido.
Línea de tiempo de la incidencia
Ve cuándo empezó la caída, cómo evolucionó y cuándo llegó la recuperación completa.
Tendencias de tiempo de respuesta
Sigue cambios de rendimiento y detecta ralentizaciones antes de que afecten a los usuarios.
Contexto de alertas en una sola vista
Checks, historial de incidentes y señales críticas permanecen juntos para investigar más rápido.
Uptime es el porcentaje de tiempo en que un servicio permanece disponible y utilizable. Un uptime monitoring service mide esa disponibilidad con comprobaciones repetidas, registra cuándo empieza y termina el downtime y convierte esos eventos en registros sobre los que tu equipo puede actuar. En vez de depender de quejas de clientes, obtienes evidencia directa de cuándo un sistema estuvo accesible, con qué frecuencia falló y si la fiabilidad mejora con el tiempo.
El availability percentage importa porque convierte el rendimiento técnico en una señal de negocio. Si un servicio central cae, la continuidad del servicio se ve afectada de inmediato: se detienen los inicios de sesión, se acumulan colas, fallan checkouts, se frenan integraciones y los equipos internos pierden visibilidad. Por eso los datos de monitor uptime deben ser claros, basados en tiempo y ligados a incidentes reales, no a snapshots ambiguos.
Para checks más orientados a páginas, contenido renderizado y experiencias de cara al cliente, empieza con website monitoring.
Muestra qué parte del tiempo un servicio estuvo realmente accesible y utilizable, no solo si la infraestructura existía.
Incluso caídas cortas interrumpen inicios de sesión, compras, flujos de trabajo, jobs programados y la confianza del cliente.
El uptime percentage da a los equipos una forma consistente de seguir la fiabilidad y compararla con expectativas de SLA.
En producción, un uptime monitor útil hace más que enviar una sola solicitud y decir arriba o abajo. Ejecuta comprobaciones regulares, confirma fallos repetidos, abre un incidente cuando la caída es real y genera alertas que ayudan al equipo correcto a responder rápido. Ese flujo reduce falsos positivos sin perder velocidad de detección.
UptimeTick ejecuta checks con la frecuencia que elijas para que puedas monitorizar uptime de forma continua en servicios críticos.
Cuando una comprobación falla, la verificación repetida ayuda a separar una caída real de un problema transitorio de red.
Los fallos confirmados se convierten en incidentes accionables con marcas de tiempo, monitores afectados y seguimiento de recuperación.
Los equipos reciben uptime alerts por email y push móvil para empezar la remediación antes de que el downtime se expanda.
Los porcentajes de uptime hacen que la fiabilidad sea más fácil de entender porque convierten la disponibilidad en un estándar compartido. También están muy ligados a los SLA, a las revisiones post-incidente y a las expectativas del cliente. Cuando un equipo dice que un servicio debe mantenerse en 99.9% de uptime, ese objetivo fija un límite práctico para el downtime aceptable en un mes.
¿Por qué importa tanto 99.9%? Porque es suficientemente exigente para hacer visibles los problemas recurrentes, pero lo bastante realista para muchos productos SaaS en crecimiento y sistemas empresariales. Si no puedes medir uptime percentage de forma consistente, es difícil saber si la fiabilidad mejora, si la respuesta es lo bastante rápida o si los objetivos de continuidad del servicio realmente se están cumpliendo.
Aproximadamente 7 horas de downtime al mes. Ese nivel puede ser doloroso para SaaS de cara al cliente o tiendas online.
Alrededor de 43 minutos de downtime al mes. Es un objetivo común de fiabilidad porque mantiene las caídas visibles y manejables.
Solo unos pocos minutos de downtime al mes. Llegar ahí suele requerir monitorización más estricta y respuesta más rápida.
Ajusta el plan al número de servicios, checks y alertas que tu equipo necesita para operar.
Uptime monitoring cubre más que una sola página pública. Los servicios fiables dependen de que endpoints, infraestructura, certificados y procesos en segundo plano permanezcan disponibles al mismo tiempo.
Cuando necesitas reachability del host en la capa de red, añade ICMP ping monitoring.
Para endpoints que deben devolver el status code y el payload correctos, suma API monitoring.
Website uptime monitoring es la primera línea de defensa para los servicios digitales. Te dice si una experiencia orientada al cliente es accesible, devuelve la respuesta esperada y se mantiene disponible durante picos de tráfico, deploys o fallos de terceros.
UptimeTick comprueba sitios web públicos y apps web por HTTP(s), ayudando a los equipos a detectar outages, seguir la latencia y confirmar que se sirve una página real y no una plantilla de error o una respuesta rota.
Server uptime monitoring se centra en si la infraestructura detrás de tu servicio es accesible. Eso importa para servidores de aplicación, nodos internos, sistemas edge y cualquier entorno donde la conectividad de red sea la señal más temprana del problema.
Con ping monitoring y port monitoring, UptimeTick ayuda a los equipos de operaciones a detectar downtime en los sistemas que sostienen tráfico de clientes, herramientas administrativas y cargas internas antes de que un incidente pequeño se convierta en una interrupción mayor.
Una API puede devolver 200 y aun así romper el flujo de negocio, así que API uptime monitoring necesita más que un simple handshake. Los checks fiables de API confirman que los endpoints responden a tiempo y devuelven el contenido o estado del que depende tu aplicación.
UptimeTick ayuda a developers y equipos SaaS a monitorizar uptime en servicios de autenticación, APIs centrales del producto, webhooks e integraciones con partners, donde la disponibilidad afecta de forma directa a la experiencia del usuario y a la automatización.
Algunos incidentes de disponibilidad son fallos de confianza y no downtime puro. Un certificado caducado o mal configurado puede volver un servicio efectivamente inaccesible aunque el host siga respondiendo.
UptimeTick combina SSL monitoring con uptime checks para que los equipos detecten riesgo de certificados antes, eviten caídas prevenibles y mantengan continuidad para navegadores, APIs y clientes automatizados que requieren TLS válido.
No todas las cargas importantes exponen un endpoint. Jobs programados, pipelines de importación, workers en segundo plano y tareas de backup suelen fallar en silencio si no verificas que reportan a tiempo.
Heartbeat monitoring permite a UptimeTick confirmar que esas señales esperadas llegan como se planificó. Cuando un job pierde su ventana, tu equipo recibe un uptime alert ligado a un proceso específico en lugar de descubrir el problema cuando los clientes ya notan datos faltantes o retrasos.
Lanza un monitor en minutos y mantén visibles desde un solo dashboard los checks de websites, servers, APIs, SSL y heartbeat.
Los outages ligados a renewal quedan fuera de muchos app checks, así que una cobertura más amplia también necesita domain expiry monitoring.
La detección temprana es lo que convierte uptime monitoring en una herramienta operativa y no solo de reporting. Cuanto antes identifiques un outage o una caída de fiabilidad, antes podrás proteger la experiencia del cliente, reducir la pérdida de ingresos y mantener a los equipos alineados sobre la cronología real del incidente.
Para detectar problemas de certificate antes de que se conviertan en incidentes de availability, combina uptime tracking con SSL monitoring.
Los usuarios pueden perdonar un incidente, pero los problemas repetidos de disponibilidad hacen que tu servicio parezca poco fiable.
El downtime puede bloquear trials, transacciones, inicios de sesión y renovaciones mientras suben los costes de soporte e ingeniería.
Outages persistentes y disponibilidad inestable pueden perjudicar la fiabilidad de rastreo y debilitar la experiencia del tráfico orgánico.
Sin detección temprana, los equipos pierden la línea de tiempo necesaria para aislar causas, coordinar la respuesta y proteger la continuidad del servicio.
UptimeTick está diseñado para equipos que quieren uptime monitoring práctico sin un proceso pesado de configuración. Obtienes los tipos de monitor que necesitan los sistemas reales en producción, uptime alerts rápidas, visibilidad móvil e historial que hace más fácil explicar la fiabilidad.
Crea un uptime monitor en minutos con checks HTTP(s), ping, port, SSL, heartbeat, domain y keyword en un solo producto.
Las notificaciones por email y push móvil ayudan a que las personas correctas vean los incidentes antes que los clientes.
Usa las apps móviles de UptimeTick para revisar estado de monitores, incidentes activos y recuperación cuando estás lejos del escritorio.
Revisa uptime percentage, duración de incidentes y tendencias de fiabilidad para retrospectivas, reporting y conversaciones de SLA.
Distintos equipos usan uptime monitoring por motivos distintos, pero el objetivo es el mismo: mantener disponibilidad y reducir el impacto del downtime antes de que afecte a usuarios u operaciones.
Sigue apps de cara al cliente, endpoints de auth, jobs en segundo plano y flujos de billing donde el uptime afecta directamente a retención y expansión.
Monitoriza storefronts, checkouts, callbacks de pago y salud SSL para que el downtime no interrumpa ingresos silenciosamente.
Vigila herramientas admin, intranets, endpoints VPN y workflows programados de los que dependen los equipos cada día.
Monitoriza endpoints públicos y privados que impulsan apps móviles, integraciones, automatización y servicios para partners.
Respuestas claras para equipos que comparan uptime monitors y evalúan su encaje operativo.
Uptime monitoring es el proceso de comprobar si un servicio se mantiene disponible con el tiempo, detectar downtime y alertar a los equipos cuando un outage o incidente afecta a la fiabilidad.