ICMP mantiene el check ligero
Ping usa una solicitud simple a nivel de red, lo que lo convierte en una forma rápida de probar la reachability básica sin una transacción completa de aplicación.
Ping monitoring con UptimeTick ayuda a developers, sysadmins, equipos SaaS y operadores de infraestructura a verificar rápido la host reachability, monitorizar la ping latency con el tiempo y activar ping alerts cuando cambia la network availability antes de que un incidente pequeño se convierta en un outage visible.
Checks de ICMP reachability
Confirma si un host es alcanzable en la capa de red sin esperar a que los usuarios lo reporten.
Visibilidad de latency y packet loss
Detecta tiempos de respuesta más lentos, rutas inestables y paquetes perdidos que suelen aparecer antes de un outage completo.
Ping alerts instantáneas
Avisa rápido al equipo correcto cuando fallos repetidos muestran que un host está caído o degradado.

Checks, incidentes, contexto de alerts e historial de recovery quedan en una sola vista para investigar más rápido.
Línea de tiempo de la incidencia
Ve cuándo empezó la caída, cómo evolucionó y cuándo llegó la recuperación completa.
Tendencias de tiempo de respuesta
Sigue cambios de rendimiento y detecta ralentizaciones antes de que afecten a los usuarios.
Contexto de alertas en una sola vista
Checks, historial de incidentes y señales críticas permanecen juntos para investigar más rápido.
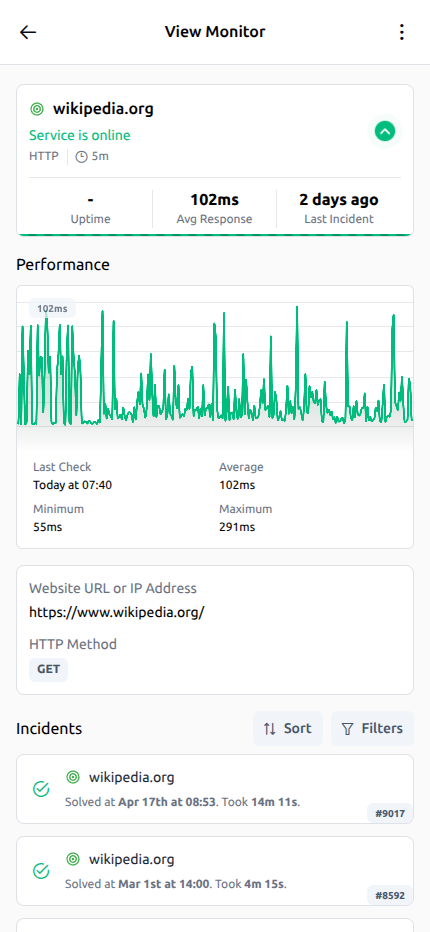
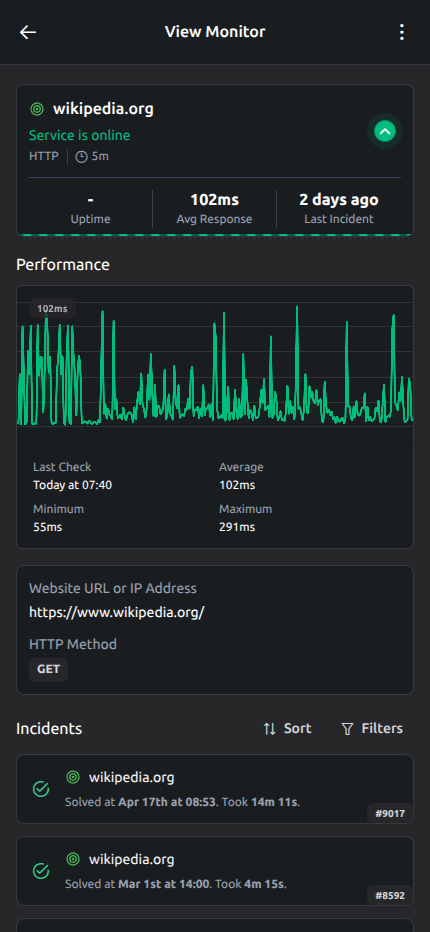
Ping monitoring es el proceso de enviar solicitudes ICMP echo regulares a un host y medir si responde. En términos simples, un ping monitor le pregunta a un servidor, router o dispositivo de red: "¿Eres alcanzable ahora mismo?". Si el host responde, el check confirma la network availability básica. Si no responde, tu equipo recibe una señal temprana de que la reachability puede estar rota en algún punto entre el nodo de monitorización y el sistema objetivo.
Una ping monitoring tool útil también mide tiempos, no solo estado up o down. Cada ICMP reply muestra cuánto tardó el viaje de ida y vuelta, lo que ayuda a los equipos a entender las tendencias de latency y detectar inestabilidad antes de un outage completo. Cuando suben los tiempos de respuesta, las replies se vuelven inconsistentes o aumenta el packet loss, puedes investigar un problema de red en desarrollo antes de que se acumulen errores de aplicación, tickets de soporte o quejas de clientes.
Si quieres reporting de availability para el resto de tu stack, conecta estos checks con uptime monitoring más amplio.
Ping usa una solicitud simple a nivel de red, lo que lo convierte en una forma rápida de probar la reachability básica sin una transacción completa de aplicación.
Si un host no puede responder a un ping, puede haber un problema de routing, firewall, provider o infraestructura bloqueando el tráfico por completo.
La latency muestra si un host simplemente es alcanzable o si el rendimiento de red está empezando a degradarse bajo carga o condiciones de fallo.
En producción, ping uptime monitoring debe hacer más que enviar una sola sonda y cambiar una luz de estado. Necesita checks ICMP recurrentes, datos de tiempo, visibilidad de packet loss y reglas de alert que distingan una oscilación breve de red de un problema real de host availability. Esa combinación ayuda a los equipos a responder rápido sin crear ruido innecesario.
UptimeTick envía checks ICMP en el intervalo que elijas para que puedas observar la network reachability de forma continua en lugar de depender de pruebas manuales.
Cada reply exitosa registra el tiempo de ida y vuelta y da a los equipos una forma práctica de monitorizar la ping latency e identificar cambios en el rendimiento de red.
Cuando se pierden replies o son inconsistentes, el packet loss se vuelve visible y ayuda a explicar una conectividad degradada antes de que el host pase a estar totalmente unreachable.
Si fallan checks de ping repetidos, UptimeTick abre un incident y envía ping alerts para que el equipo pueda investigar el outage mientras la línea temporal sigue fresca.
Los problemas de red suelen aparecer antes en la capa de reachability que en la capa de aplicación. Un ping monitor da a los equipos una señal rápida de que algo cambió en routing, connectivity, latency o entrega de paquetes, lo que permite iniciar la incident response antes de que los usuarios sufran una interrupción mayor del servicio.
Los picos de latency y el packet loss suelen aparecer antes de un outage completo, dando tiempo a los equipos para investigar enlaces, providers o infraestructura sobrecargada.
Cuando un host deja de responder a checks ICMP, los equipos pueden separar un fallo de reachability de un bug de aplicación y acotar antes la investigación.
La detección temprana acorta el tiempo entre el fallo y la respuesta, lo que limita el impacto en clientes y mejora la gestión del incidente.
Una ping monitoring tool fiable debe mostrar más que una insignia roja o verde. Los equipos necesitan suficiente detalle de red para entender si la availability es estable, se está degradando o ya está en territorio de incident.
Si el host responde pero aún debes validar la experiencia del visitante, añade website monitoring.
El seguimiento de latency ayuda a los equipos a ver si un host alcanzable sigue respondiendo dentro de límites normales. Una red puede seguir técnicamente up mientras el rendimiento empeora, por lo que es importante monitorizar la ping latency en vez de tratar cada reply exitosa como igualmente saludable.
Con datos históricos de tiempo, UptimeTick hace más fácil comparar el comportamiento normal con periodos de incident, ventanas de mantenimiento o problemas del provider. Ese contexto ayuda a decidir si una ralentización es aislada, recurrente o probable origen de un outage mayor.
El packet loss suele ser la pista que falta en network ping monitoring. Un host puede responder a algunos checks y fallar en otros, creando un patrón que parece aleatorio para los usuarios pero que se vuelve claro al seguir resultados ICMP consecutivos a lo largo del tiempo.
Ver tasas de pérdida junto a la latency ayuda a los equipos a distinguir una connectivity inestable de un outage claro. Esto importa en enlaces WAN, rutas de cloud networking, dispositivos edge e infraestructuras donde los fallos intermitentes pueden ser tan dañinos como una desconexión total.
Ping uptime monitoring da a los equipos una señal directa de que un host es alcanzable en la red. Esto es especialmente útil para servidores, appliances y componentes de infraestructura donde la availability básica importa antes de pasar a checks de capas superiores.
Los ping checks no sustituyen al HTTP(s) o al port monitoring, pero sí responden a otra pregunta: ¿puede el tráfico llegar al host en absoluto? Usados juntos, ayudan a entender si el problema es network reachability, service availability o ambos.
Cuando un host parece unreachable desde una región pero saludable desde otra, el problema puede estar en un transit provider, una ruta regional o un segmento local de red, y no en el propio objetivo. Los checks desde múltiples ubicaciones reducen las suposiciones al añadir perspectiva.
Para equipos distribuidos y servicios globales esto importa porque un incidente local también puede ser un incidente real para clientes. Comparar resultados entre ubicaciones da a los responders una forma más rápida de entender el alcance y priorizar la siguiente acción.
Las ping alerts rápidas son lo que convierte los datos de monitorización en acción operativa. Cuando un host falla checks repetidos, la persona adecuada necesita una señal clara con tiempo, cambio de estado y suficiente contexto para empezar el troubleshooting de inmediato.
UptimeTick envía alerts rápido y mantiene disponible el historial del incidente después, para que los equipos puedan responder en el momento y revisar exactamente cuándo empezaron a aparecer el packet loss, los cambios de latency o los fallos del host.
Ping monitoring funciona mejor donde lo primero que necesitas confirmar es la network reachability. Da a los ingenieros una forma rápida de validar si el tráfico todavía puede llegar a infraestructura y servicios críticos.
Cuando un host reachable sigue sirviendo un endpoint roto, API endpoint monitoring ayuda a aislar la capa de aplicación.
Monitoriza servidores físicos, máquinas virtuales y edge hosts para confirmar reachability antes de empezar un troubleshooting más profundo de la aplicación.
Usa ping checks junto a HTTP monitoring para distinguir problemas de red a nivel host de fallos de lógica en la aplicación o en el endpoint.
Sigue dispositivos de red y puntos de routing donde el packet loss o una latency más alta pueden señalar un incidente mayor de infraestructura.
Verifica que el host detrás de un sitio es alcanzable aunque después los HTTP checks ayuden a confirmar contenido, status codes y comportamiento de cara al usuario.
Observa cloud instances, targets de load balancer e infraestructura regional donde la network availability puede cambiar durante eventos de escalado o incidentes del provider.
UptimeTick da a los equipos una ping monitoring tool clara y práctica sin obligarlos a trabajar en un flujo fragmentado. Puedes configurar checks rápido, recibir alerts veloces, revisar el historial de incidentes y mantener la visibilidad de red disponible en desktop y móvil.
Para servicios en producción que también dependen de TLS trust, combina los checks de red con SSL certificate monitoring.
Crea un ping monitor en minutos y añade checks HTTP(s), port, SSL, heartbeat, keyword y domain cuando necesites una cobertura más amplia.
Las notificaciones por email y móvil ayudan a los responders a actuar rápido ante fallos del host en vez de esperar reportes de outage por parte de usuarios.
Revisa cuándo cambió la latency, cuándo apareció el packet loss y cuándo el host pasó a estar unreachable en incidentes anteriores.
Usa las apps móviles de UptimeTick para seguir el estado del monitor, los incidentes activos y el progreso de recovery cuando no estás en tu escritorio.
Empieza con checks esenciales de conectividad y amplía la cobertura cuando crezcan tus hosts y entornos.
Respuestas claras para equipos que comparan ping monitors y checks de uptime basados en ICMP.
Ping monitoring es la práctica de enviar checks ICMP a un host a intervalos regulares para confirmar reachability, medir latency y detectar problemas de availability como packet loss o outage completo.