Los endpoint checks verifican más que reachability
Un buen check confirma que la ruta responde correctamente, no solo que el host aceptó una conexión.
API monitoring con UptimeTick ayuda a developers, equipos backend, founders de SaaS y equipos DevOps a monitorizar API endpoints por availability, latency, comportamiento de timeout e invalid responses para que los incidentes se detecten antes de afectar flujos de producto, integraciones o usuarios.
Endpoint reliability monitoring
Sigue si las rutas críticas de API permanecen accesibles, rápidas y válidas con el tiempo.
Response validation más allá del uptime
Confirma status codes, contenido esperado e integridad del payload en lugar de confiar en una simple comprobación de conexión.
API downtime alerts rápidas
Avisa al equipo correcto cuando un endpoint se ralentiza, entra en timeout o empieza a devolver respuestas incorrectas.
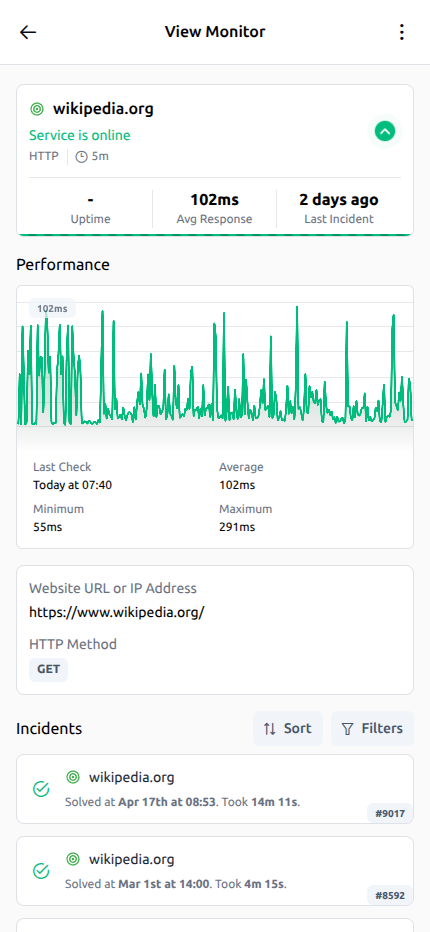
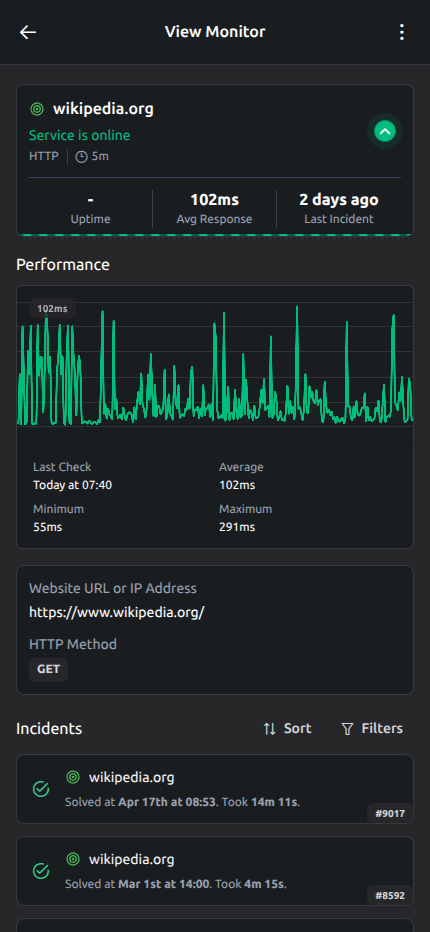
Checks, incidentes, contexto de alerts e historial de recovery quedan en una sola vista para investigar más rápido.
Línea de tiempo de la incidencia
Ve cuándo empezó la caída, cómo evolucionó y cuándo llegó la recuperación completa.
Tendencias de tiempo de respuesta
Sigue cambios de rendimiento y detecta ralentizaciones antes de que afecten a los usuarios.
Contexto de alertas en una sola vista
Checks, historial de incidentes y señales críticas permanecen juntos para investigar más rápido.
API monitoring es la práctica de enviar solicitudes repetidas a un endpoint y comprobar si la respuesta coincide con lo que espera tu aplicación. Una API monitoring tool no solo pregunta si una ruta está online. Sigue endpoint availability, response codes, latency, comportamiento de timeout y contenido de la respuesta para que los equipos sepan si una API es realmente utilizable en producción.
Esto importa porque las APIs suelen fallar en silencio. Un servidor puede seguir respondiendo mientras el flujo de negocio ya está roto: la autenticación puede degradarse, un webhook puede dejar de entregar el payload correcto, un endpoint de pagos puede volverse lento o una integración con partners puede empezar a devolver invalid data. Sin endpoint monitoring activa, estos fallos pueden quedar invisibles hasta que usuarios, clientes o sistemas dependientes empiecen a reportarlos.
Para una vista de fiabilidad más amplia entre endpoints, sites, certificates y jobs, conecta esta página con uptime monitoring.
Un buen check confirma que la ruta responde correctamente, no solo que el host aceptó una conexión.
Una API puede seguir técnicamente disponible mientras devuelve el status code incorrecto, entra en timeout o produce un payload defectuoso.
Los problemas backend suelen aparecer primero en integraciones rotas y workflows retrasados, mucho antes de que llegue un ticket de soporte.
En producción, API uptime monitoring debe reflejar cómo los sistemas reales dependen de un endpoint. Eso significa enviar solicitudes periódicas, comprobar el response code, medir latency, vigilar timeouts y validar el contenido devuelto. El objetivo no es solo saber que algo respondió, sino saber si la API respondió bien y con suficiente rapidez para sostener el workflow que depende de ella.
UptimeTick envía requests a las rutas API que definas para que la salud del endpoint se compruebe de forma continua y no manual.
Los HTTP status codes esperados ayudan a confirmar que el endpoint devolvió un resultado correcto en lugar de un redirect, un client error o un server error.
Si un endpoint tarda demasiado o no devuelve respuesta dentro de la ventana esperada, el monitor puede marcar un timeout incident antes de que los usuarios sufran workflows bloqueados.
Los keyword checks y las comprobaciones de respuesta ayudan a confirmar que el payload sigue conteniendo los campos, valores o marcadores de los que depende tu integración.
Una API response monitoring fiable debe revelar más que downtime total. Muchos incidentes de API empiezan como fallos parciales, comportamiento degradado de la respuesta o invalid data devuelta por un servicio que sigue siendo alcanzable.
Los problemas de certificate y TLS también pueden romper endpoints sanos, así que combina los API checks con SSL monitoring.
Una de las señales más tempranas en API status monitoring es un response code inesperado. Una ruta que debería devolver 200 puede empezar a devolver 401, 403, 404, 429 o 500 según el tipo de fallo. Estos cambios suelen apuntar a errores de despliegue, problemas de autorización, dependencias rotas o sobrecarga upstream.
Seguir cambios en los response codes importa porque los fallos de aplicación no siempre se ven como downtime desde fuera. Una API puede seguir respondiendo mientras rompe todos los workflows que esperan una respuesta concreta de éxito.
Un endpoint puede seguir disponible mientras se vuelve cada vez más lento por carga, contención en la base de datos o esperas de servicios terceros. Por eso una API monitoring tool debe medir latency de forma continua, no solo confirmar que llegó una respuesta en algún momento.
Las tendencias de latency ayudan a entender si el rendimiento se está degradando hacia un incident. Si una ruta normalmente responde en unos cientos de milisegundos y de repente empieza a tardar segundos, los usuarios pueden sentir el impacto antes de que haya un outage completo.
Los timeouts suelen ser de los fallos de API más dañinos porque dejan workflows abiertos mientras no vuelve nada útil. Esto puede afectar checkouts, sign-ins, callbacks, sincronización móvil, queue workers y cualquier automatización que espere una respuesta rápida de un endpoint backend.
Cuando timeout detection forma parte de la monitorización, los equipos pueden identificar estos bloqueos como un tipo claro de incidente en vez de tratarlos como simple lentitud. Eso acelera mucho el troubleshooting.
Un response 200 no garantiza que una API haya hecho lo correcto. Una ruta puede devolver un status code exitoso mientras el payload carece de un campo obligatorio, contiene un valor erróneo o incluye un mensaje de error dentro de un response body que sigue pareciendo técnicamente válido.
Por eso response validation importa dentro de API uptime monitoring. Comprobar JSON markers esperados, fragmentos de mensaje o keywords ayuda a detectar fallos funcionales que los checks de status no verán.
Algunos incidentes de API empiezan en la capa de transporte y confianza en vez de dentro de la lógica de aplicación. Un problema de certificado puede volver inutilizable un endpoint para clientes, automatizaciones e integraciones que requieren TLS válido.
Combinar API checks con SSL monitoring ayuda a detectar incidentes relacionados con certificados antes de que se conviertan en fallos de autenticación, webhooks fallidos o tráfico roto con partners.
Cubre primero tus APIs críticas y amplía después la validación de endpoints, latencia y respuestas.
Un buen endpoint monitoring combina señales de uptime, response validation y alerting para que los equipos actúen tanto sobre fallos evidentes como sobre errores más sutiles.
Si los fallos pueden empezar en la capa de host o routing, usa network reachability monitoring junto a los endpoint checks.
Los endpoint uptime checks confirman que una ruta puede alcanzarse de forma consistente y devuelve una respuesta en lugar de fallar por completo. Esta es la base del seguimiento de API availability y la primera señal que la mayoría de equipos necesita durante un incidente.
Bien usados, estos checks ayudan a los equipos backend y DevOps a ver si el fallo está aislado a una sola ruta, se está extendiendo por un servicio o está ligado a un problema mayor de infraestructura.
API response monitoring debe hacer visible la latency, no solo el uptime. Una ruta que sigue online pero se vuelve lenta sigue creando un problema real para dashboards, apps móviles, colas y flujos síncronos de producto.
Los datos históricos de tiempo ayudan a comparar el comportamiento normal con despliegues, picos de tráfico, fallos de dependencias e incidentes conocidos. Ese contexto es clave para entender si el rendimiento es estable o se está degradando.
Muchos equipos backend necesitan más que validar el status code. Necesitan saber que la API sigue devolviendo la estructura o los valores de los que dependen sus aplicaciones. En endpoints basados en JSON, eso significa comprobar campos, marcadores o valores esperados dentro del response body.
UptimeTick ayuda a validar el contenido esperado de la respuesta para que una request técnicamente exitosa no oculte un payload roto o un resultado incompleto.
Los keyword checks son útiles cuando un endpoint debe devolver una frase conocida, un identificador, un nombre de campo o un business-state marker. Esto es práctico para APIs con valores predecibles en la respuesta y para casos donde un parser completo no es necesario.
Usados con criterio, los response keyword checks ayudan a detectar regresiones silenciosas en auth flows, acknowledgements de webhooks, integraciones con partners y APIs operativas.
La monitorización solo importa cuando lleva a acción. Cuando un endpoint falla checks, supera una latency aceptable, entra en timeout o empieza a devolver contenido inválido, el equipo correcto necesita una alert clara y suficiente contexto para responder de inmediato.
UptimeTick convierte los fallos confirmados de API en incidentes accionables con alerts y registros históricos, lo que facilita acortar la distancia entre detección y respuesta.
Las APIs están detrás de funciones de producto, automatizaciones, integraciones con partners, flujos de facturación y herramientas internas. Cuando fallan en silencio, el daño se propaga más rápido de lo esperado porque la rotura suele aparecer primero en sistemas dependientes.
Las integraciones internas y de terceros dependen de un comportamiento predecible del endpoint, no solo de una URL alcanzable.
Response validation y el seguimiento de timeouts exponen incidentes que los usuarios pueden no notar hasta que los workflows ya están rotos.
APIs estables sostienen la fiabilidad del producto, la confianza de partners y menos escalaciones de soporte.
Monitoring y alerts rápidas ayudan a responder antes de que clientes, partners o usuarios internos sean los primeros en reportar el problema.
UptimeTick ofrece una API monitoring tool práctica con los checks necesarios para endpoints reales en producción. Puedes empezar rápido, validar responses, recibir alerts rápidas y mantener accesible el historial de incidentes sin montar un workflow de monitorización fragmentado.
Crea endpoint checks en minutos con HTTP(s) monitoring, keyword validation, SSL tracking y tipos de monitor complementarios en una sola plataforma.
Las notificaciones por email y móvil ayudan a actuar rápido cuando un endpoint falla, se ralentiza o empieza a devolver invalid responses.
Revisa timelines de incidentes, comportamiento de response y fallos anteriores para que el debugging y el post-incident se apoyen en datos reales.
Usa las apps móviles de UptimeTick para revisar el estado del monitor y los incidentes activos cuando no estás en tu workstation.
Equipos distintos usan API monitoring por razones distintas, pero el objetivo común es el mismo: mantener endpoints lo bastante fiables como para que los workflows de producto e integración no fallen en silencio.
Monitoriza endpoints de autenticación, cuentas, billing, search y product data que alimentan funciones para clientes y operaciones internas.
Sigue rutas de transacción, autorización y callback donde timeout incidents o invalid responses pueden afectar ingresos de inmediato.
Observa flujos de webhook inbound y outbound para que fallos de entrega, payloads rotos y regresiones de latency no rompan automatizaciones en silencio.
Monitoriza APIs privadas entre servicios, sistemas admin y capas de automatización donde fallos backend ocultos pueden propagarse por toda la operación.
Respuestas claras para equipos que evalúan endpoint monitoring y herramientas de API uptime monitoring.
Para páginas renderizadas y contenido orientado al usuario, encaja mejor website monitoring para experiencias visibles.
API monitoring es el proceso de comprobar endpoints de forma recurrente para confirmar availability, validar response codes y contenido, medir latency y detectar incidentes como timeouts o invalid payloads.