ICMP kontrolü hafif tutar
Ping, basit bir network-level request kullanır. Bu da tam bir application işlemi olmadan temel reachability testini hızlıca yapmayı sağlar.
UptimeTick ile ping monitoring; geliştiricilerin, sysadmin’lerin, SaaS ekiplerinin ve altyapı operatörlerinin host reachability durumunu hızlıca doğrulamasına, zaman içinde ping latency verisini izlemesine ve küçük bir incident görünür bir outage’a dönüşmeden önce network availability değişimlerinde ping alerts almasına yardımcı olur.
ICMP reachability kontrolleri
Kullanıcı bildirimini beklemeden bir host’un network katmanında erişilebilir olup olmadığını doğrulayın.
Latency ve packet loss görünürlüğü
Tam outage öncesinde ortaya çıkan yavaş yanıt sürelerini, dengesiz rotaları ve kaybolan paketleri görün.
Anlık ping alerts
Tekrarlanan hatalar host’un down veya degraded olduğunu gösterdiğinde doğru ekibi hızlıca haberdar edin.

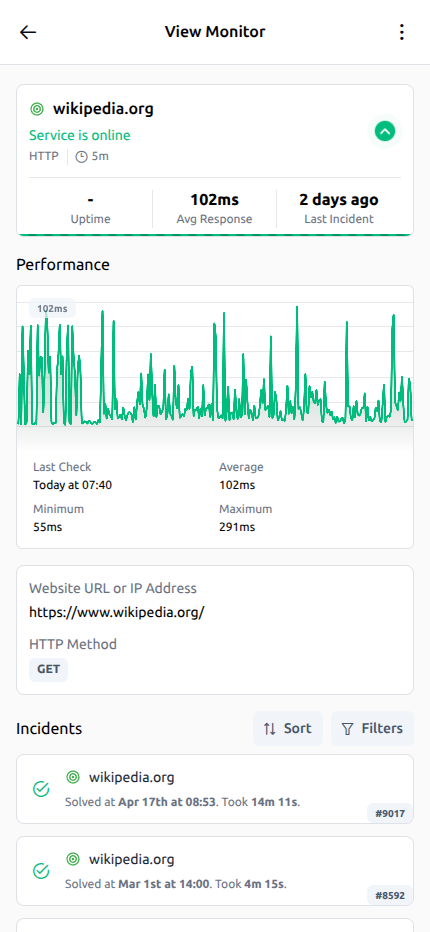
Kontroller, incident geçmişi, alarm bağlamı ve toparlanma bilgileri tek ekranda durur; ekipler daha hızlı aksiyon alır.
Kesinti zaman çizelgesi
Kesintinin ne zaman başladığını, nasıl ilerlediğini ve ne zaman toparlandığını tek akışta görün.
Yanıt süresi trendleri
Performans değişimlerini izleyin ve yavaşlamaları kullanıcı deneyimini etkilemeden önce fark edin.
Alarm bağlamı tek görünümde
Kontroller, olay geçmişi ve kritik sinyaller aynı ekranda birleşerek incelemeyi hızlandırır.
Ping monitoring, bir host’a düzenli ICMP echo request gönderip yanıt verip vermediğini ölçme sürecidir. Basitçe söylemek gerekirse bir ping monitor, sunucuya, router’a veya network cihazına "Şu anda erişilebilir misin?" diye sorar. Host yanıt verirse kontrol temel network availability durumunu doğrular. Yanıt vermezse, monitoring noktası ile hedef sistem arasındaki reachability zincirinde bir sorun olabileceğine dair ekibinize erken sinyal verir.
İyi bir ping monitoring tool yalnızca up veya down durumunu değil, zamanlamayı da ölçer. Her ICMP reply, gidiş-dönüş süresinin ne kadar sürdüğünü gösterir. Bu da ekiplerin latency trendlerini anlamasına ve tam bir outage oluşmadan önce kararsızlığı fark etmesine yardımcı olur. Yanıt süreleri yükseldiğinde, reply’lar tutarsızlaştığında veya packet loss arttığında, application hataları, support ticket’ları ve müşteri şikayetleri birikmeden gelişen network sorununu araştırabilirsiniz.
Stack’in geri kalanı için availability reporting istiyorsanız bu kontrolleri daha geniş uptime monitoring ile birleştirin.
Ping, basit bir network-level request kullanır. Bu da tam bir application işlemi olmadan temel reachability testini hızlıca yapmayı sağlar.
Bir host ping’e yanıt veremiyorsa, trafiği tamamen engelleyen routing, firewall, provider veya altyapı kaynaklı bir problem olabilir.
Latency, host’un yalnızca erişilebilir olup olmadığını değil, yük veya hata koşullarında network performansının bozulmaya başlayıp başlamadığını da gösterir.
Production ortamında ping uptime monitoring, tek bir probe gönderip durum ışığını değiştirmekten fazlasını yapmalıdır. Düzenli ICMP kontrolleri, zamanlama verisi, packet loss görünürlüğü ve kısa süreli network dalgalanmasını gerçek host availability probleminden ayıran alert kuralları gerekir. Bu kombinasyon, gereksiz gürültü oluşturmadan ekiplerin hızlı hareket etmesini sağlar.
UptimeTick, seçtiğiniz aralıkta ICMP kontrolleri gönderir; böylece manuel testlere güvenmek yerine network reachability durumunu sürekli izleyebilirsiniz.
Her başarılı reply, round-trip süresini kaydeder ve ekiplere ping latency verisini izlemekle network performansındaki değişimleri belirlemek için pratik bir yol sunar.
Reply’lar kaçırıldığında veya tutarsızlaştığında packet loss görünür hale gelir ve host tamamen unreachable olmadan önce degraded connectivity durumunu açıklamaya yardımcı olur.
Tekrarlanan ping kontrolleri fail verdiğinde UptimeTick bir incident açar ve responders ekibinin outage’ı zaman çizelgesi henüz sıcakken araştırabilmesi için ping alerts gönderir.
Network problemleri çoğu zaman application katmanından önce reachability katmanında görünür. Bir ping monitor; routing, connectivity, latency veya packet delivery tarafında bir şeylerin değiştiğine dair ekiplerin hızlı sinyal almasını sağlar. Böylece kullanıcılar daha geniş bir service disruption yaşamadan incident response süreci başlayabilir.
Latency spike’ları ve packet loss çoğu zaman tam outage öncesinde ortaya çıkar; bu da ekiplere linkleri, provider’ları veya aşırı yüklenmiş altyapıyı araştırmak için zaman kazandırır.
Bir host ICMP kontrollerine yanıt vermeyi bıraktığında ekipler reachability failure ile application bug’ını ayırabilir ve araştırma alanını daha hızlı daraltabilir.
Erken tespit, hata ile müdahale arasındaki süreyi kısaltır; bu da müşteri etkisini sınırlar ve incident yönetimini iyileştirir.
Güvenilir bir ping monitoring tool, kırmızı veya yeşil rozetten fazlasını göstermelidir. Ekiplerin availability durumunun stabil mi, bozuluyor mu, yoksa zaten incident seviyesinde mi olduğunu anlaması için yeterli network detayına ihtiyacı vardır.
Host yanıt veriyor olsa bile ziyaretçi deneyimini doğrulamak gerekiyorsa website monitoring ekleyin.
Latency takibi, ekiplerin erişilebilir bir host’un hâlâ normal sınırlar içinde yanıt verip vermediğini görmesini sağlar. Bir network teknik olarak up kalabilir ama performans kötüleşebilir; bu yüzden her başarılı reply’ı eşit derecede sağlıklı kabul etmek yerine ping latency verisini izlemek önemlidir.
Tarihsel zamanlama verisiyle UptimeTick; normal davranışı incident dönemleri, maintenance pencereleri veya provider sorunlarıyla karşılaştırmayı kolaylaştırır. Bu bağlam, yavaşlamanın izole mi, tekrarlayan mı yoksa daha büyük bir outage’a dönüşme ihtimali mi taşıdığını anlamaya yardımcı olur.
Packet loss, network ping monitoring tarafında çoğu zaman eksik kalan ipucudur. Bir host bazı kontrollere yanıt verip bazılarını kaçırabilir; bu da kullanıcılar için rastgele görünen ama zaman içinde ardışık ICMP sonuçları izlendiğinde net biçimde ortaya çıkan bir desen oluşturur.
Loss oranlarını latency ile birlikte görmek, ekiplerin dengesiz connectivity ile net bir outage’ı ayırt etmesini sağlar. Bu; WAN linkleri, cloud networking path’leri, edge cihazlar ve aralıklı hataların tam kopuş kadar zararlı olabildiği altyapılar için kritiktir.
Ping uptime monitoring, ekiplere bir host’un network üzerinde erişilebilir olduğuna dair doğrudan sinyal verir. Bu özellikle higher-layer kontrollere geçmeden önce temel availability bilgisinin önemli olduğu sunucular, appliance’lar ve altyapı bileşenleri için faydalıdır.
Ping kontrolleri HTTP(s) veya port monitoring’in yerini almaz, ancak farklı bir soruya cevap verir: trafik host’a hiç ulaşabiliyor mu? Birlikte kullanıldıklarında, sorunun network reachability mi, service availability mi yoksa ikisi birden mi olduğunu anlamaya yardımcı olurlar.
Bir host bir bölgeden unreachable görünürken başka bir bölgeden sağlıklı görünüyorsa, sorun hedefin kendisinden çok transit provider, bölgesel routing path veya yerel network segmentinde olabilir. Çoklu lokasyon kontrolleri, ek perspektif sunarak tahmine dayalı çalışmayı azaltır.
Dağıtık ekipler ve global servisler için bu önemlidir; çünkü lokal bir incident bile gerçek bir müşteri incident’ı olabilir. Sonuçları lokasyonlar arasında karşılaştırmak, responders ekibinin kapsamı daha hızlı anlamasını ve sonraki aksiyonu önceliklendirmesini sağlar.
Hızlı ping alerts, monitoring verisini operasyonel aksiyona dönüştüren şeydir. Bir host tekrarlanan kontrollerde fail verdiğinde doğru responder’ın zamanlama, durum değişimi ve hemen troubleshooting başlatmaya yetecek kadar bağlam içeren net bir sinyale ihtiyacı vardır.
UptimeTick uyarıları hızlı gönderir ve sonrasında incident geçmişini erişilebilir tutar; böylece ekipler anında yanıt verebilir ve packet loss, latency değişimleri veya host hatalarının tam olarak ne zaman başladığını sonradan da inceleyebilir.
Ping monitoring, network reachability bilgisinin önce doğrulanması gereken senaryolarda en iyi sonucu verir. Mühendislere trafiğin kritik altyapı ve servislere hâlâ ulaşıp ulaşmadığını doğrulamak için hızlı bir yol sunar.
Reachable bir host yine de bozuk endpoint döndürebileceği için application katmanını ayırmakta API endpoint monitoring yardımcı olur.
Daha derin application troubleshooting başlamadan önce reachability durumunu doğrulamak için fiziksel sunucuları, sanal makineleri ve edge host’ları izleyin.
Host-level network sorunlarını application veya endpoint logic hatalarından ayırmak için ping kontrollerini HTTP monitoring ile birlikte kullanın.
Packet loss veya yüksek latency’nin daha geniş bir altyapı incident’ını işaret edebileceği network cihazlarını ve routing noktalarını izleyin.
Daha sonra HTTP kontrolleri içerik, status code ve user-facing davranışı doğrulasa bile site arkasındaki host’un erişilebilir olduğunu teyit edin.
Scaling event’leri veya provider incident’ları sırasında network availability değişebilen cloud instance’ları, load balancer target’larını ve bölgesel altyapıyı izleyin.
UptimeTick, ekiplere parçalı bir workflow’a zorlamadan net ve pratik bir ping monitoring tool sunar. Kontrolleri hızlıca kurabilir, hızlı alert’ler alabilir, incident geçmişini inceleyebilir ve network görünürlüğünü masaüstü ile mobilde sürdürebilirsiniz.
TLS trust’a da bağlı production servisler için network kontrollerini SSL certificate monitoring ile eşleştirin.
Dakikalar içinde bir ping monitor oluşturun; daha geniş kapsama ihtiyacınız olduğunda HTTP(s), port, SSL, heartbeat, keyword ve domain kontrollerini ekleyin.
Email ve mobil bildirimler, kullanıcı outage bildirimlerini beklemek yerine responders ekibinin host hatalarına hızlıca aksiyon almasını sağlar.
Geçmiş incident’larda latency’nin ne zaman değiştiğini, packet loss’un ne zaman başladığını ve host’un ne zaman unreachable olduğunu inceleyin.
Masa başında değilken monitor durumu, aktif incident’lar ve recovery sürecini takip etmek için UptimeTick mobil uygulamalarını kullanın.
Temel erişilebilirlik kontrolleriyle başlayın; daha fazla host ve ortam ekledikçe kapsamı genişletin.
Ping monitor araçlarını ve ICMP tabanlı uptime kontrollerini karşılaştıran ekipler için net cevaplar.
Ping monitoring, bir host’a düzenli aralıklarla ICMP kontrolleri göndererek reachability durumunu doğrulama, latency ölçme ve packet loss veya tam outage gibi availability sorunlarını tespit etme pratiğidir.